This blog post is available in audio format as well. You can listen using the player below or download the mp3 file for listening at your convenience.
Section 1 | Project Introduction
YouTubeGPT is a novel application that leverages the cutting-edge capabilities of Long Context Language Models (LCLMs) to enhance how users interact with YouTube content. This project is built on the recent advancements in LCLMs, which have significantly expanded the context windows that language models can handle, allowing for more complex reasoning over larger amounts of information.
The core idea behind YouTubeGPT is to extract comprehensive information from a YouTube video, including the video title, timestamped transcript, timestamped descriptions of the visual content, the name of the uploading channel, and the video description. This rich dataset is then fed into an LCLM, enabling users to “talk to their YouTube video.” This allows them to interact not only with the audio and visual components but also with the temporal aspects of the content, gaining a deeper understanding of the sequence of events—not just what happened, but when it happened within the video.
By giving an LCLM access to this comprehensive data, the model can reason about the content in a holistic manner, taking into account what was said, what was shown, and the timing of these events. This approach offers a rich and highly interactive experience, allowing users to delve deeper into the video’s content and gain a thorough understanding of the material presented.
The user experience is designed to be as seamless as possible. The only action required from the user is to copy and paste the URL of a YouTube video into the chat box. YouTubeGPT handles all the necessary steps, including video downloading, processing, and context retrieval, allowing the user to start interacting with the video content quickly and effortlessly.
To further enhance the user experience, YouTubeGPT stores the processed data from each video in a secure database. This means that if you or another user wants to converse with the same video at a later time, the system can instantly retrieve the stored data without needing to repeat the processing steps. As a result, users can start interacting with the video content immediately, making the experience both efficient and convenient.
YouTubeGPT is publicly accessible at https://youtubegpt.net.
Section 2 | Project Motivation
In recent years, a significant trend in the development of language models is the continuous increase in the size of their context windows. As companies release newer and more advanced language models, these expanded context windows allow the models to process and reason over larger amounts of information in a single pass, which enhances their capabilities.
For instance, consider Figure 1:
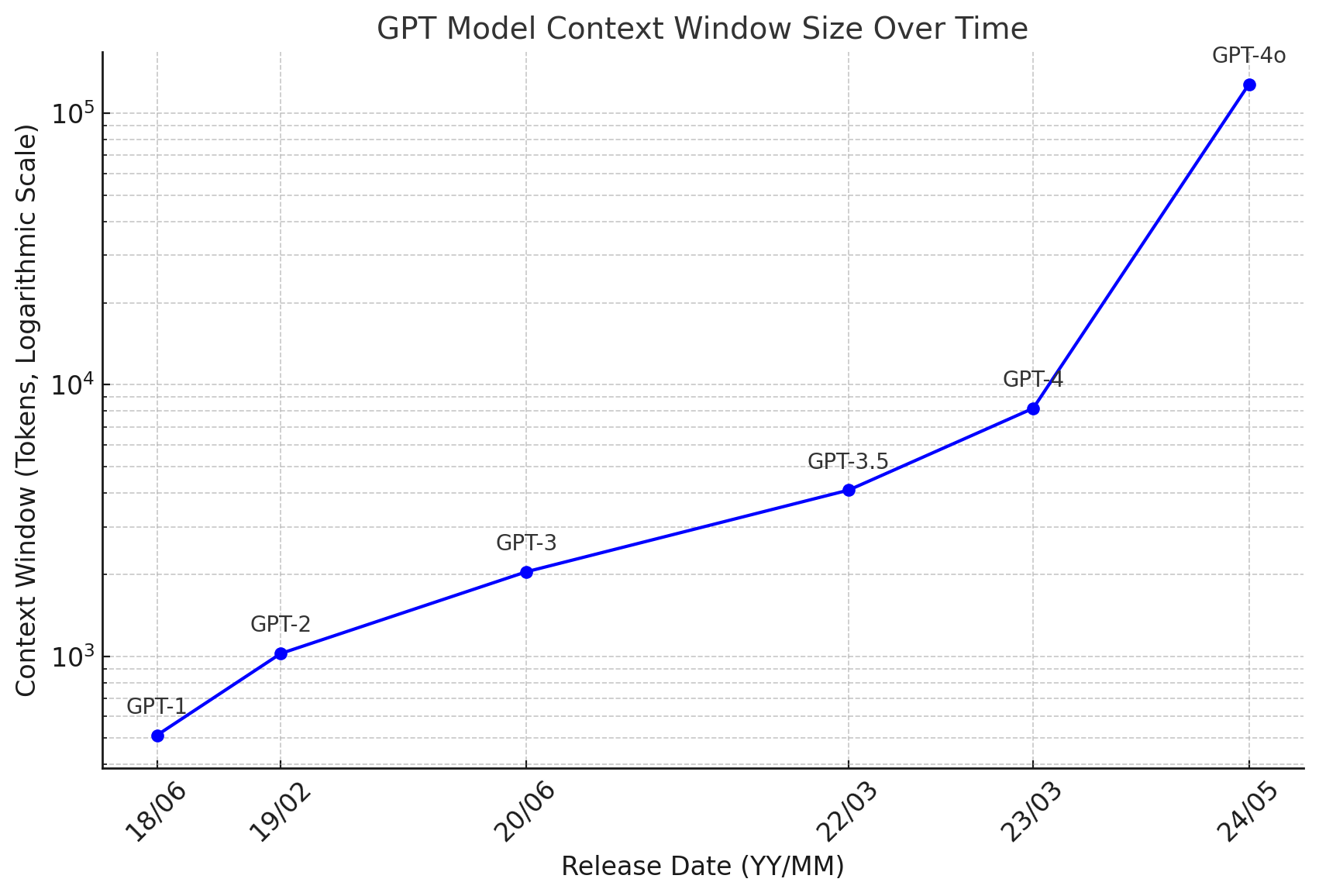
Figure 1 illustrates the context window sizes of the GPT model family over time. We can observe a clear trend: OpenAI has consistently increased the context window size with each iteration, from GPT-1 to GPT-4o, significantly expanding the model’s ability to handle extensive input. This trend highlights the ongoing effort to make these models more capable and useful by allowing them to consider more information simultaneously.
The Google DeepMind team recently published a paper titled Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More? (Lee et al. 2024), which delves into the potential of Long-Context Language Models (LCLMs) to revolutionize tasks traditionally reliant on external tools like retrieval systems or databases. These LCLMs are designed to ingest and process entire corpora of information directly, which simplifies complex tasks by reducing the need for specialized tools and pipelines. This paradigm shift is particularly exciting because it opens up new possibilities for applications that require reasoning over large, multifaceted datasets.
Section 2.1 | Long Context Language Models (LCLMs)
LCLMs, as discussed in the paper by the Google DeepMind team, represent a significant advancement in AI. These models can process long sequences of data, up to millions of tokens, without breaking down the input into smaller, disconnected segments. This capability enables LCLMs to perform tasks that were previously unmanageable, such as complex in-context retrieval and reasoning.
Consider Figure 2:
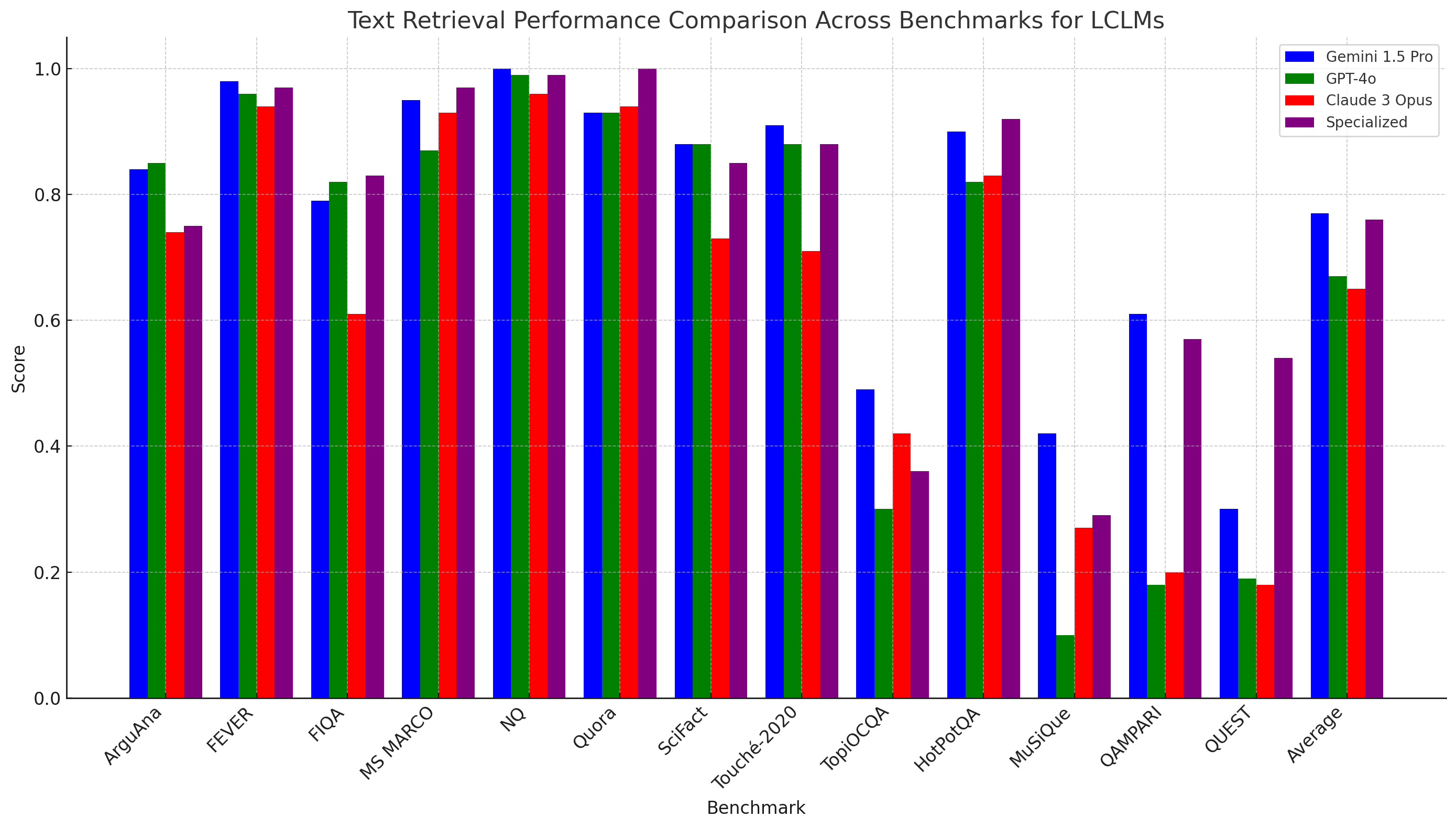
Figure 2, based on data from the Google DeepMind LCLM paper, shows a comparison of text retrieval performance across various benchmarks for LCLMs, demonstrating their ability to rival specialized systems in many areas.
The graph reveals that while specialized models often excel at particular tasks due to their fine-tuning and domain-specific optimizations, LCLMs like Gemini 1.5 Pro, GPT-4o, and Claude 3 Opus exhibit strong, competitive performance across a wide range of benchmarks.
In many cases, these LCLMs either match or surpass the performance of specialized models, particularly in text retrieval tasks where the model’s ability to understand and process large amounts of context in a single pass is crucial. This highlights the versatility and growing capability of LCLMs to perform complex tasks without the need for extensive task-specific customization.
The utility of LCLMs extends to various domains, including text, visual, and audio retrieval, as well as SQL-like reasoning and retrieval-augmented generation (RAG). The paper introduces LOFT, a benchmark that provides a rigorous testing ground for these models, highlighting their potential to simplify and improve tasks that require large context processing.
Section 2.2 | YouTubeGPT and the Power of Corpus-in-Context Prompting
One of the recent advancements in the field of AI is a concept called Corpus-in-Context (CiC) prompting. This technique, highlighted in recent research by the Google DeepMind team, involves leveraging the large context capabilities of Long Context Language Models (LCLMs) to incorporate and reason over an extensive corpus of information within a single model prompt. By embedding the entire corpus into the model’s context, CiC prompting eliminates the need for complex, external retrieval systems and allows for more sophisticated reasoning and retrieval tasks to be performed directly within the model.
Building on this innovative concept, I developed YouTubeGPT to transform a YouTube video into a dynamic corpus, enabling what I call Video-in-Context Prompting. For this, I chose the GPT-4o inference model as the LCLM of choice due to its advanced context handling capabilities. In this application, the “corpus” is an aggregated collection of text documents derived from processing various modalities, including the video’s audio, visual, and textual components. This comprehensive dataset, which includes the title, timestamped transcript, visual descriptions, and metadata, forms the basis for the model to interact with the video content in a highly contextual and nuanced manner.
With YouTubeGPT, users can engage with a video in ways that were previously impossible. The LCLM can answer questions, retrieve specific moments, and provide contextually relevant information based on the entire video corpus. This means that whether a user is looking to find out what was said at a particular timestamp, understand the sequence of visual events, or query the content of the video, YouTubeGPT can provide precise, context-aware responses.
Section 3 | Conclusion
YouTubeGPT introduces a powerful new approach to engaging with video content by harnessing the capabilities of Long Context Language Models (LCLMs). By transforming video data into a comprehensive and context-rich format, YouTubeGPT enables a deeper, more interactive experience that is particularly well-suited for video Q&A. As LCLMs continue to advance, tools like YouTubeGPT have the potential to significantly change the way we interact with and derive insights from online content, making these interactions more intuitive and informative.